Joining the Threads
Sonification
There has always been an inquiry and curiosity among composers about how the world can be translated into sound. In a way, much of what constitutes the world is already sounding. Therefore, there is no need to translate—only to listen. But how does something that is non-sounding become sound?
The process of translating something non-sonic into sound is known as sonification.*Technically, sonification is defined as a transformation of data relations into perceived relations in an acoustic signal for the purposes of facilitating communication or interpretation. In Gregory Kramer et al., "Sonification Report: Status of the Field and Research Agenda," Faculty Publications, Department of Psychology, University of Nebraska-Lincoln 444 (2010), https://digitalcommons.unl.edu/psychfacpub/444. sonification aims essentially to translate some information into sound, at the same time as maintaining comprehensible quantitative relationships that are present in this sonified information in the sounding result.
In my practice, sometimes, sonification embodies a symbolic representation of sound in the form of conventional musical notation. I understand this process as one of symbolic sonification, and I will explain this concept in more detail later. Other times, I am interested in a direct mapping process between a source and its sonified result as an audio signal. This is what is usually done as a direct –and somewhat conventional– process of audification.*Bruce N Walker and Michael A Nees, "Theory of sonification," in The sonification handbook, ed. Thomas Hermann, Andy Hunt, and John G. Neuhoff (Logos Publishing House, 2011). I will also discuss an example of this later on.
Symbolic sonification
I use the term symbolic sonification*I came up with this term as a creation of my own. However, I recently found a previous article that employs the term in a similar way, by implementing symbolic sonification of L-systems. See Adam James Wilson, "A Symbolic Sonification of L-Systems," CUNY Academic Works (2009). as a process that represents changes in certain sonic dimensions as changes in a musical symbolic dimension. The word symbolic refers to the outcome of the process as symbolic musical information in the form of a score, but also symbolic in the sense that the source of the sonification is not overtly perceived in the outcome of the process. Symbolic sonification is a method that yields some musical representation, but the connection between the source and the outcome is not necessarily perceptually relatable.
For symbolic sonification to exist, certain musical parameters –the conventional ones are pitch, duration, and dynamics, but others can also be proposed– must be formalized as a numeric representation (such as MIDI cents, velocity, milliseconds, or other numeric values), and the sonified data must be constrained or scaled such that a direct mapping into one another is feasible.
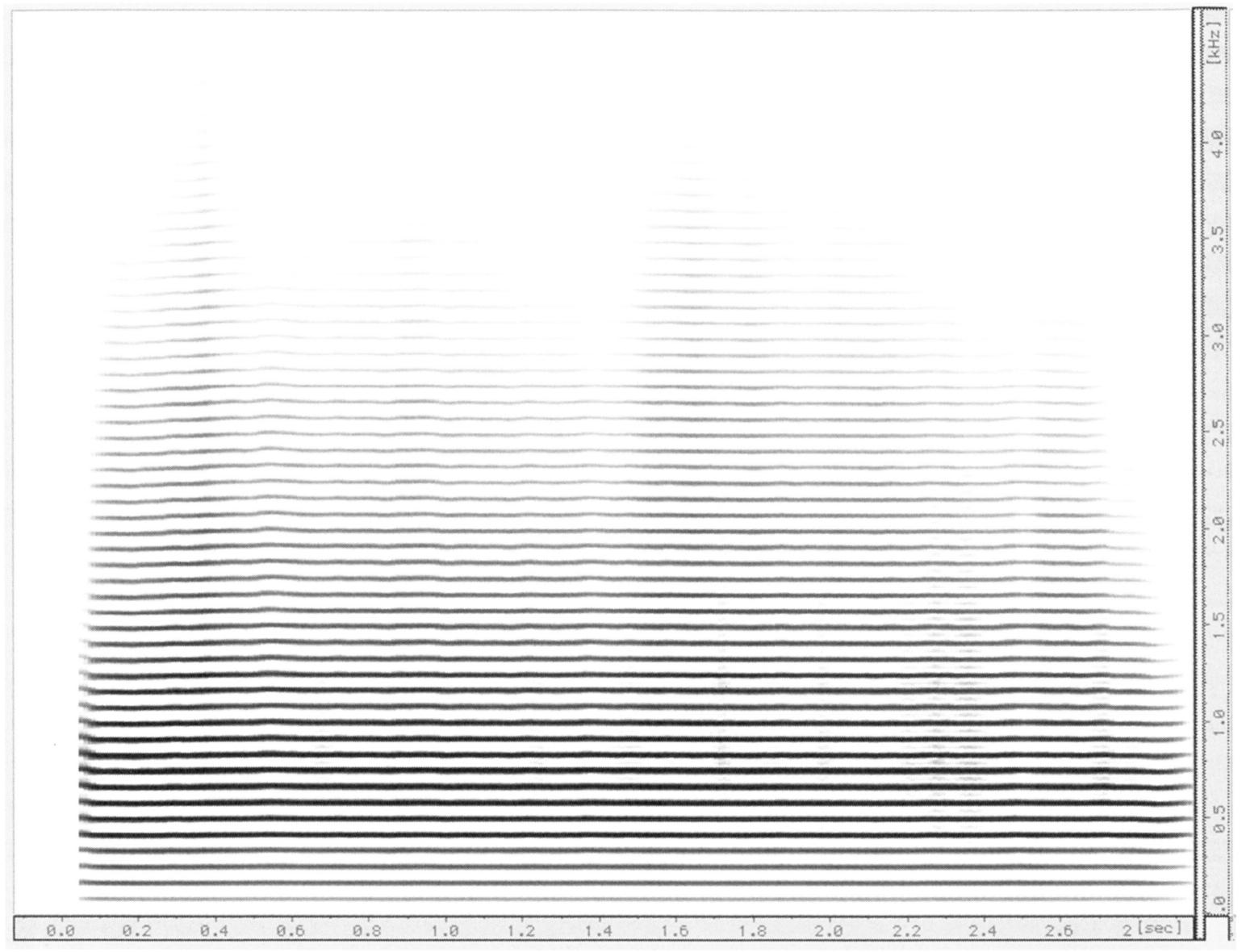
Along with the evolution of Western music, there are many historical examples of symbolic sonification. However, it is the symbolic sonification of acoustic information, at some point, became interesting to me. Initially, this process was defined as instrumental resynthesis.*For an in-depth discussion of the concept of instrumental resynthesis, see Joshua Fineberg, "Guide to the basic concepts and techniques of spectral music," Contemporary Music Review 19, no. 2 (2000), https://doi.org/10.1080/07494460000640271, and James O'Callaghan, "Mimetic Instrumental Resynthesis," Organised Sound 20, no. 2 (2015), https://doi.org/10.1017/S1355771815000114 and was extensively developed by the French spectralist school around the 1970s. Instrumental resynthesis became possible with the advent of the spectrogram.*A spectrogram is a visual representation of the spectrum of frequencies in a sound signal as they vary with time. This new tool allowed for the detailed visual observation of the dynamic evolution of the spectral components of sound –in addition to its known abstract quantities and magnitudes.
This inspired some composers to replicate these processes using acoustic instruments, creating a form of additive synthesis that mirrors actual sound partials. The goal was for these partials to merge perceptually into a unified sound, forming a complex harmonic structure. Instrumental resynthesis, therefore, aimed at achieving a fusion between harmony and timbre, with one of the primary goals of spectralist composers being the exploration of all forms of fusion and the thresholds that define them.
The most iconic example of instrumental resynthesis is the opening bars of Gerard Grisey’s Partiels for 18 Musicians (1975), where the spectrum of a trombone sound is recreated by the instruments of the ensemble playing its partials. The result is not the physical recreation of the sound of a trombone but a sounding metaphor of it.

An example of symbolic sonification closely tied to the concept of instrumental resynthesis of acoustic sounds in my work is found in the piece Oscillations (iii). In this piece, the piano chords serve as an instrumental resynthesis of the harmonic spectrum of a bell-like sound produced by a prepared C2 note on the same piano. The preparation is relatively simple, achieved by placing two magnets near the tuning pegs. Since the bell-like sound reappears throughout the piece, the chords may be perceptually connected to it. However, upon listening, this connection does not stand out or become perceptually apparent –especially if the listener is unaware of it beforehand. This process is shown in the image below. The rhythmic part has been slightly modified “by hand” from the original quantization.

Another similar example is also found in Oscillations (iii). In this case, the accordion part is the symbolic sonification of the sound produced by rubbing a superball beneath the piano’s soundboard. As with the previous example, while the accordion and the rubbed piano sound simultaneously, it is challenging to perceptually link the two elements. Instead, the combined sound complex functions metaphorically, although some harmonic or timbral fusion takes place.

Not limited to the resynthesis of acoustic spectrums, the French spectralists investigated the possibility of instrumentally resynthesizing artificial sound spectrums, as well as the development of more advanced techniques of synthesis and digital signal processing. For example, spectrums that resulted from different types of modulation of signals, such as frequency modulation (FM)*Frequency Modulation synthesis (FM) is a method of sound synthesis in which the frequency of a waveform is modulated by another signal. FM synthesis can produce both harmonic and inharmonic sounds. Harmonic sounds arise when the modulator is harmonically related to the carrier, while inharmonic, bell-like, or percussive tones are created using modulators with non-integer frequency ratios. A modulation index can be adjusted to add more complexity to the sound. Complex FM spectrums have a bell-like quality. or ring modulation (RM).*Ring Modulation synthesis (RM) is a type of signal processing function resulting in an output signal generated usually from the combination of two signals: a carrier signal and a modulator signal. The outcome of the ring modulation process is an output signal constituting the sum and the subtraction of those two signals. These output frequencies are called sidebands.
Some composers had already used signal modulations in the past primarily as a method to process and alter the timbre of acoustic instrumental sounds. For example, Karlheinz Stockhausen employed two ring modulator devices in his piece Mantra for two pianos and percussion (1970). The sounds of each piano are ring-modulated with a different sine tone at each section of the thirteen large segments of the composition. The pianists use knobs to re-tune these devices at the beginning of each section. The modulated sound is then projected through loudspeakers positioned behind and above the performers.

The new approach by the French Spectralists was to resynthesize these signal modulation processes in the symbolic domain of musical pitches. The most influential example of this work for me is the piece Gondwana (1980) by Tristan Murail. In it, Murail sought to evoke large bell-like sonorities in the orchestra, employing FM. For this, three values are necessary: the carrier and the modulator, whose frequencies interact to produce a spectrum, and a modulation index. The process is described by the following formula where c is the carrier, m is the modulator, and I is the modulation index:
Below, it can be observed how this is applied by Murail in the first orchestral aggregate of Gondwana. The carrier is a G5 (784 Hz), the modulator is a G#4 (415.3 Hz; the calculations are realized in hertz and must be transformed from frequencies into musical pitches), and from left to right, it can be seen how the resulting sounds change due to increasing the modulation index:

In Gondwana, Murail organizes a succession of harmonic spectra in order of increasing harmonicity. The consonance or dissonance of the interval between the carrier and modulator directly influences the harmonic or inharmonic nature of the modulation. The piece begins with a highly inharmonic aggregate based on the dissonant interval G#–G, progressing toward greater harmonicity as the carrier-modulator intervals become more consonant.

Despite their visual complexity, these aggregates sound less intricate due to the fusion created by precise frequency relationships, intensities, and timbres. In terms of dynamics, Murail opted for a simplified approach, associating higher modulation indices with weaker intensities rather than modeling FM with complete mathematical fidelity.
I will discuss my use of symbolic sonification of a modulated spectrum in the piece I am a Strange Loop later in this section. Before that, I need to discuss another form of symbolic sonification, in which I became very interested at some point in my compositional journey: the musical reconstruction of speech sounds.
Several composers have done this throughout the history of WACM. For example, David Evan*David Evan, "Compositional Control of Phonetic / Nonphonetic Perception," Perspectives of New Music 25, no. 1 (1987). and Clarence Barlow,*Clarence Barlow, "On Music Derived from Language" Proceedings of the 3rd International Symposium on Systems Research in the Arts and Humanities, Baden-Baden, Germany (2009). among others. However, one of the most compelling examples of this approach is Jonathan Harvey’s Speakings for Orchestra and Electronics (2007). In this piece, Harvey explores the instrumental production of speech-like aspects of sounds in a non-linguistic context, using spectral information from speech to create a voice-like quality in instrumental timbre and harmony, evoking associations with the human voice. To achieve this, he employs two primary processes: one based on instrumental additive synthesis or instrumental resynthesis and another involving digital signal processing of the orchestral instruments, using resonating filters to shape their spectrum to resemble speech sounds.
Concerning the first process, in the first section of Speakings, Harvey orchestrates the sound of a baby’s scream (labeled as “baby scream” in the last bar of p. 6 in the score). By analyzing the frequency and amplitude data of an audio sample of a baby scream, he assigns these frequencies and relative amplitudes to the orchestra, re-creating this spectrum through instrumental additive synthesis. Harvey employs the violins’ higher range in clusters, mimicking formants as frequency bands rather than discrete pitches. The melodic contour of the cluster and the final descending glissando further replicate the timbral morphology of the baby’s scream.*For a more detailed analysis of the piece Speakings by J. Harvey see Gabriel José Bolaños Chamorro, "An Analysis of Jonathan Harvey’s ‘Speakings’ for Orchestra and Electronics," Ricercare 13, no. 13 (2021), https://doi.org/10.17230/ricercare.2020.13.4.

An example of the second process can be observed on p. 24 of the score, where the clusters in the piano are processed using a resonant filter that emphasizes or attenuates certain spectral bands in the sound simulating speech formants. This makes the sounds approach timbrally to speech.

A more recent approach to this comes from the composer Fabio Cifariello Ciardi, who introduced a framework for resynthesizing the prosodic flow of speech.*Fabio Cifariello Ciardi, "Strategies and tools for the sonification of prosodic data: A composer's perspective," Proceedings of the 26th International Conference on Auditory Display (ICAD 2021) (2021), https://doi.org/https://doi.org/10.21785/icad2021.041. The interesting aspect of Ciardi’s approach is that he is concerned with prosody (i.e., duration, accent, volume, tempo, pitch, and contour variations in the vocal signal) rather than fully complex speech information based on precise formants or specific spectral structures for specific speech sounds. Ciardi’s approach is based on an adaptive strategy of data reduction since, compared to speech, prosodic information has a much lower complexity. The model takes speech raw audio as input and outputs MIDI and MusicXML data, enabling samplers and notation software to both aurally represent and visually display this information.
This approach has been developed by Ciardi in compositions for solo instruments, ensembles, and orchestras. The design of this system provides the possibility of balancing accuracy in the translation and playability across different instrumental settings. For example, a more precise and complex notation for solo players or a lower-resolution lattice is necessary when scoring for large ensembles or orchestras.

An example of a process of symbolic sonification that uses speech sounds as a source can be found in the piece Versificator – Render 3. Here, the sonification consists of a translation of the spectral structure and duration of vocalic phonetic sound into musical pitches and durations, metaphorically embodying the general principle of the Text-To-Speech (TTS) synthesizer. However –and differently from Ciardi’s and Harvey’s approach– the source for the sonification does not come from audio signals. Rather, it comes from a database of normalized formant frequencies and durations for English-spoken vowels.*This database can be found in Hillenbrand et al., "Acoustic characteristics of American English vowels." These formant structures translated into musical representation yield several distinctive musical harmonic fields. Potentially, this approach allows for generating fixed harmonic fields in correspondence to each speech sound.

Another example of symbolic sonification of speech was already discussed in the piece Elevator Pitch for cello and electronics. Here, the musical material comes from sonifying Donald Trump’s spoken phrase, “The time for empty talk is over.” This approach is relatively similar to Harvey’s and Ciardi’s, namely, using an FFT analysis of the sound to identify the most salient spectral cues. In this case, I discarded the information on formants and maintained only the fundamental frequency. This was later translated from an SDIF*SDIF, "Sound Description Interchange Format," is a standard for the codification and interchange of a variety of sound descriptions. SDIF was jointly developed by IRCAM and CNMAT. file into a roll-type notation system and later quantized.
Audification
Artists have explored diverse sources for sonification, using them either as starting points for further compositional refinement or as finished works derived from the direct results of this process. With the advancement of computational processing, large datasets, such as collections of numbers, databases,*See for example, Fede Camara Halac’s work on the sonification of databases: Federico Nicolás Cámara Halac, "Database Music: A History, Technology, and Aesthetics of the Database in Music Composition" (Ph.D., New York University, 2019). and real-time data streams,*See for example the work Sounding Tides, a sonification and visualization of 50 years of data from the Brisbane tides. Created by the composer Erik Griswold, the climate social scientist Rebecca Cunningham, and the creative coder Steve Berrick for Curiocity Brisbane 2022 , the work takes the form of a kinetic sound installation and an interactive smartphone app. It can be accessed here: https://www.clockedout.org/soundingtides. can now serve as sources for direct translation into sound or audification.
During my artistic research position, I had the opportunity to experiment with the audification of brain signals using fNIRS helmets. This was made possible through a collaboration between the Bergen Group on Auditory Perception, led by Dr. Karsten Specht (Faculty of Psychology, UiB), and the project Sounding Philosophy, led by Dr. Dániel Péter Biró (Grieg Academy, KMD, UiB)*More on Sounding Philosophy here: https://www.researchcatalogue.net/view/634973/634974. in conjunction with Thomas Hummel at the SWR Experimentalstudio.*Visit the SWR Experimental Studio website here: https://www.swr.de/swrkultur/musik-klassik/experimentalstudio/index.html. The use of this highly delicate and expensive equipment for artistic research was facilitated and conducted under the supervision of Dr. Karsten Specht, Professor and Deputy Dean of the Department of Biological and Medical Psychology of the University of Bergen.
The use of brain signals in sonification or audification processes is not a new concept. Many artists have explored the development of musical systems controlled or modulated by brain activity. Ultimately, these systems serve as a form of sonification of physiological processes, a concept already familiar as biofeedback.* Donald Moss, "Chapter 7 - Biofeedback," in Handbook of Complementary and Alternative Therapies in Mental Health, ed. Scott Shannon (San Diego: Academic Press, 2002). Typically, such systems map brain readings to various acoustic or symbolic representations to manipulate or generate sound. A pioneer in these investigations was David Rosenboom.*Rosenboom founded the Experimental Aesthetics Lab at York University in Toronto. The lab attracted a diverse group of artists, including prominent figures like John Cage and LaMonte Young. Some of the early results were documented in D. Rosenboom, Biofeedback and the Arts: Results of Early Experiments (Aesthetic Research Centre of Canada, 1976). https://books.google.no/books?id=NkIXAQAAIAAJ See in addition David Rosenboom, "Extended Musical Interface with the Human Nervous System: Assessment and Prospectus," Leonardo 32, no. 4 (1999), https://doi.org/10.1162/002409499553398.
In more recent times, the use and development of interfaces to use brain readings for musical purposes has developed quite extensively, as a field known as Brain-Computer Musical Interfaces (BCMI). A notable researcher in this area is Eduardo Reck Miranda.*See Eduardo Reck Miranda and Julien Castet, Guide to Brain-Computer Music Interfacing, 2014 ed. (London: Springer Nature, 2014). In addition, an important summary of forty years of investigation and experimentation in BCMI has been published in Andrew Brouse, "Petit guide de la musique des ondes cérébrales," 2012, accessed May 2, 2024, https://www.econtact.ca/14_2/brouse_brainwavemusic_fr.html. While the technology required for this type of purpose has become more affordable and portable, several attempts have been made to develop BCMI in diverse fields of musical practice, such as music performance,*S. Venkatesh, E. R. Miranda, and E. Braund, "SSVEP-based brain-computer interface for music using a low-density EEG system," Assist Technol 35, no. 5 (Sep 3 2023), https://doi.org/10.1080/10400435.2022.2084182. composition,*Caterina Ceccato et al., "BrainiBeats: A dual brain-computer interface for musical composition using inter-brain synchrony and emotional valence" (Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Association for Computing Machinery, 2023). sound synthesis,*B. Arslan et al., "A Real Time Music Synthesis Environment Driven with Biological Signals" (paper presented at the 2006 IEEE International Conference on Acoustics Speech and Signal Processing, 2006) . and improvisation.*Beste Filiz Yuksel et al., "BRAAHMS: A Novel Adaptive Musical Interface Based on Users' Cognitive State" (Proceedings of the international conference on New Interfaces for Musical Expression, Baton Rouge, Louisiana, USA, The School of Music and the Center for Computation and Technology (CCT), Louisiana State University, 2015); Sebastian Mealla et al., "Listening to Your Brain: Implicit Interaction in Collaborative Music Performances" (Proceedings of the International Conference on New Interfaces for Musical Expression, Oslo, Norway, 2011).
It is important to distinguish between two different technologies for brain readings, as they may lead to distinct artistic approaches: Functional near-infrared spectroscopy (fNIRS) and Electroencephalography (EEG). fNIRS is a non-invasive tool to continuously assess the oxygenation of localized areas of the brain. fNIRS is comparable to functional magnetic resonance imaging (fMRI). However, fNIRS relies on variances in optical absorption instead of magnetic fields. By utilizing the near-infrared spectrum, fNIRS allows light to pass through biological tissues, where it is absorbed by chromophores like oxyhemoglobin and deoxyhemoglobin.*Hasan Ayaz et al., "Chapter 3 - The Use of Functional Near-Infrared Spectroscopy in Neuroergonomics," in Neuroergonomics, ed. Hasan Ayaz and Frédéric Dehais (Academic Press, 2019). The key advantage of fNIRS lies in its portability, as it consists only of a helmet connected wirelessly to a signal amplifier and its capacity for monitoring natural-life situations, such as a musical performance.*Atsumichi Tachibana et al., "Prefrontal activation related to spontaneous creativity with rock music improvisation: A functional near-infrared spectroscopy study," Scientific Reports 9, no. 1 (2019), https://doi.org/10.1038/s41598-019-52348-6
EEG, on the other hand, measures the electrical activity of the brain by detecting voltage fluctuations resulting from ionic current flows within the neurons.* Niedermeyer's Electroencephalography: Basic Principles, Clinical Applications, and Related Fields, ed. Donald L. Schomer and Fernando H. Lopes da Silva (Oxford University Press, 2017). https://doi.org/10.1093/med/9780190228484.001.0001. EEG offers a higher temporal resolution compared to fNIRS and captures rapid neural dynamics across a broader area of the brain. However, its spatial resolution is relatively low compared to fNIRS, making it more challenging to pinpoint the precise anatomical sources of the signals.
A classic early example of the use of EEG in a piece of music is Music for a Solo Performer (1965) by Alvin Lucier. In it, the brainwaves of the performer are used to excite percussion instruments. In particular, the sought-after waves are alpha waves, which are associated with relaxation, often experienced during restful or meditative states. For this reason, the performer of this piece is sitting down with his eyes closed during the whole performance. Alpha waves, measured using an EEG, occur between 8 and 12 Hz when an individual is relaxed but awake. The rhythmic nature of these waves makes them ideal for percussive sonification, prompting Lucier and Edmond Dewan –the scientist who collaborated with Lucier for this piece– to map them directly onto percussion sounds.
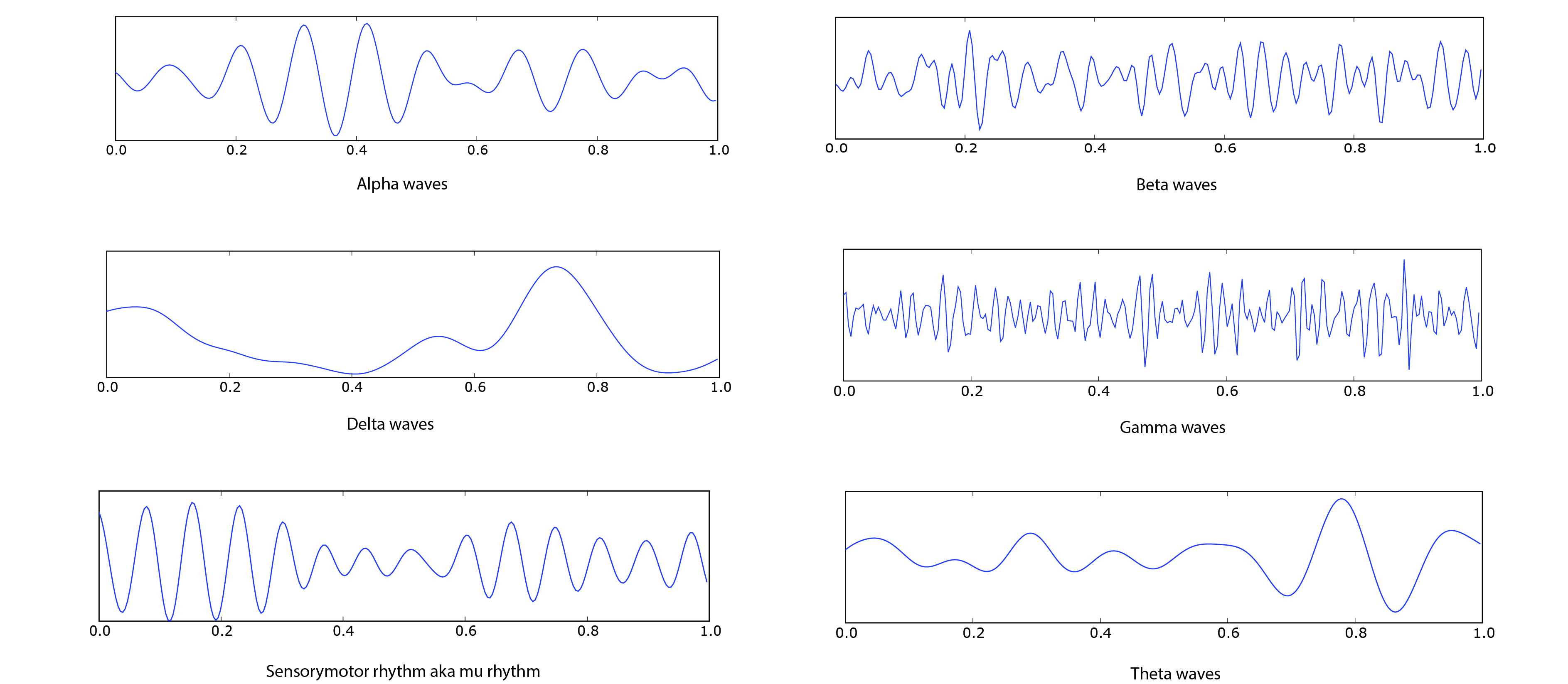
On the one hand, EEG is highly effective for mapping brainwaves with direct sensorimotor stimuli, such as limb movements, with millisecond resolution. Its high temporal efficacy allows researchers to accurately correlate brainwave activity –typically represented as peaks and valleys similar to an audio or a seismic waveform (see image above)– with bodily actions. fNIRS, on the other hand, has a lower temporal resolution, making it less suitable for fast, real-time movements. fNIRS works best at monitoring brain activity over longer periods. Compositionally, this approach is more suited for mapping slower processes that adjust synthesis parameters or gradually transform the sound.
This was the method I used with fNIRS, and I will discuss it in more detail very soon. But before diving into that, I need to cover one final compositional process related to the idea of sonification.
Parametrical Remapping
Can preexisting music be sonified? Well, music is already sound, so it doesn’t need to be. But speech is sound, too, and it can indeed be sonified! OK. To be precise, it’s not the speech itself that is sonified, but rather certain abstract structures within the acoustic signal of speech. However, when it comes to music, sonification might not be the right term. Maybe it’s more about translation—translation of music into music, but that doesn’t quite make sense either… MAPPING! How can preexisting musical structures be remapped into fresh, new musical narratives?
The idea of mapping refers to any prescribed way of assigning to each object in one set a particular object in in another set.*Encyclopedia Britannica, “mapping,” accessed April 20, 2021, https://www.britannica.com/science/mapping Remapping, thus, is defined as mapping again but also as laying out a new pattern. Parametrical remapping embodies a process by which I translate preexisting musical abstract information into constructive parameters of a new musical piece.
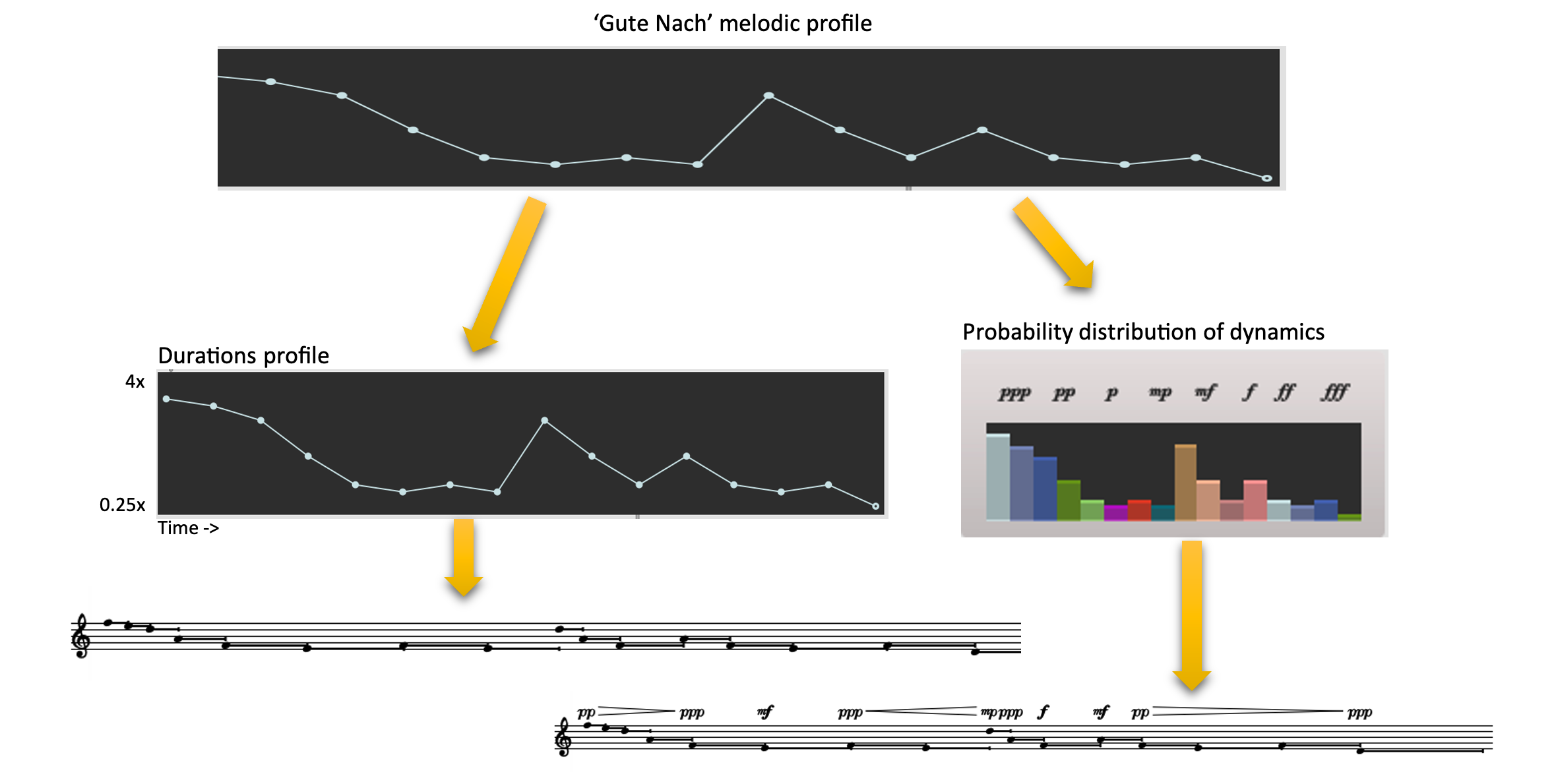
An example of this can be found in my piece Oscillations (i). Here, I use a melodic profile to reconstruct a rhythmic profile and a probabilistic dynamic distribution profile. In this case, the melodic profile is expressed as a break-point function (BPF) and becomes the source of new remappings of this BPF across diverse musical dimensions.
However, the aforementioned processes of symbolic sonification, audification, and parametric remapping are central to the creative process of I am a Strange Loop for saxophone quartet and reeds duo, which I will discuss next.