The Cognitivist Paradigm
Versificator - Render 3 * An article discussing the work in depth was originally published in Juan Sebastian Vassallo, "Machinic automation in the process of text and music composition: The versificator," NIVEL 17 (2022), https://nivel.teak.fi/carpa7/machinic-automation-in-the-process-of-text-and-music-composition/.
The use of rules in music composition, expressed in various forms, has a long history of development and practitioners. But what happens if we push this concept to the extreme, where the creative outcome is entirely shaped by rules defined through computer algorithms? Of course, the first implication of this is that, most likely, it becomes automatic. As soon as the rules are written, just by pressing a button, we can get a musical result.
This brings me to inquire: can machinic automation alone produce something artistically meaningful? Are the parameters that a system operates on compositionally sufficient to create music with depth and significance? How does incorporating automated processes in creative composition redefine the role of the human composer? Does it open up for new explorations, or does it limit our possibilities to only what can be programmed? What about the musical qualities that resist computational formalization? Can we afford to overlook these during the creative process? Furthermore, is there still space for subjectivity within the computational framework of a system? And if so, what about the potential to defy or subvert the system? If such potential exists, how might it be explored and harnessed? In this paradigm, what is thus at the core of the artwork, the program? The result? The experience?
My versificator is a modular system designed to simultaneously generate and sonify algorithmically produced text. This system automates much of the musical information generation, including pitches, durations, dynamics, and vocal articulations. Additionally, it offers the capability to automate the formal structure of a piece as well as the temporal and textural organization of the musical material. By adjusting input parameters, the system enables diverse processes of musical generation, transformation, and concatenation. In the versificator, the processes of composition and generation occur almost simultaneously –at least for the part of the process that occurs inside the system –an “outside the system” compositional aspect also exists, which I will address later. This means that the generation of musical material inherently carries its own compositional logic.
Initially, I imagined a system capable of generating text and superimposing music onto it automatically. My goal was to create nonsensical poetry and derive a musical layer (pitches and durations) based on the text’s phonological content. This approach resembles the workings of a Text-To-Speech (TTS) system. A TTS system generally receives some text input and translates it into the sound of a synthetic voice. This translation relies on the artificial recreation of acoustic information from the text by mapping letters to sounds with a particular spectral characteristic which makes us recognize them as speech sounds.* Probably the most widely used TTS synthesis method from the 1980s onwards was a method developed especially after the works of Dennis Klatt: the Klatt synthesizer. See Dennis H. Klatt, "Software for a cascade/parallel formant synthesizer," The Journal of the Acoustical Society of America 67, no. 3 (1980), https://doi.org/10.1121/1.383940. For instance, to synthesize a vowel, a TTS system uses information about its spectral structure –such as fundamental frequency, formants, and durations– to generate speech. In my system, however, the result is a musical unit that maps a phoneme’s spectral structure into a symbolic musical representation.
The main interface of the versificator is a large Max patch that contains various subpatches and abstractions. The main patch provides a global overview and core functionality, while each subpatch functions as a generative module. The system’s core functionalities rely heavily on two Max external libraries: BACH*https://www.bachproject.net/ and MOZ'Lib. The BACH library offers a sophisticated music notation interface, while MOZ'Lib includes an implementation of PWConstraints, a Lisp-based constraint-solving engine developed by Mikael Laurson for the PWGL software.*See Mikael Laurson, "PatchWork: a visual programming language and some musical applications," (Sibelius Academi, 1996). The library PWConstraints was ported to Max by Örjan Sandred and Julien Vincenot.
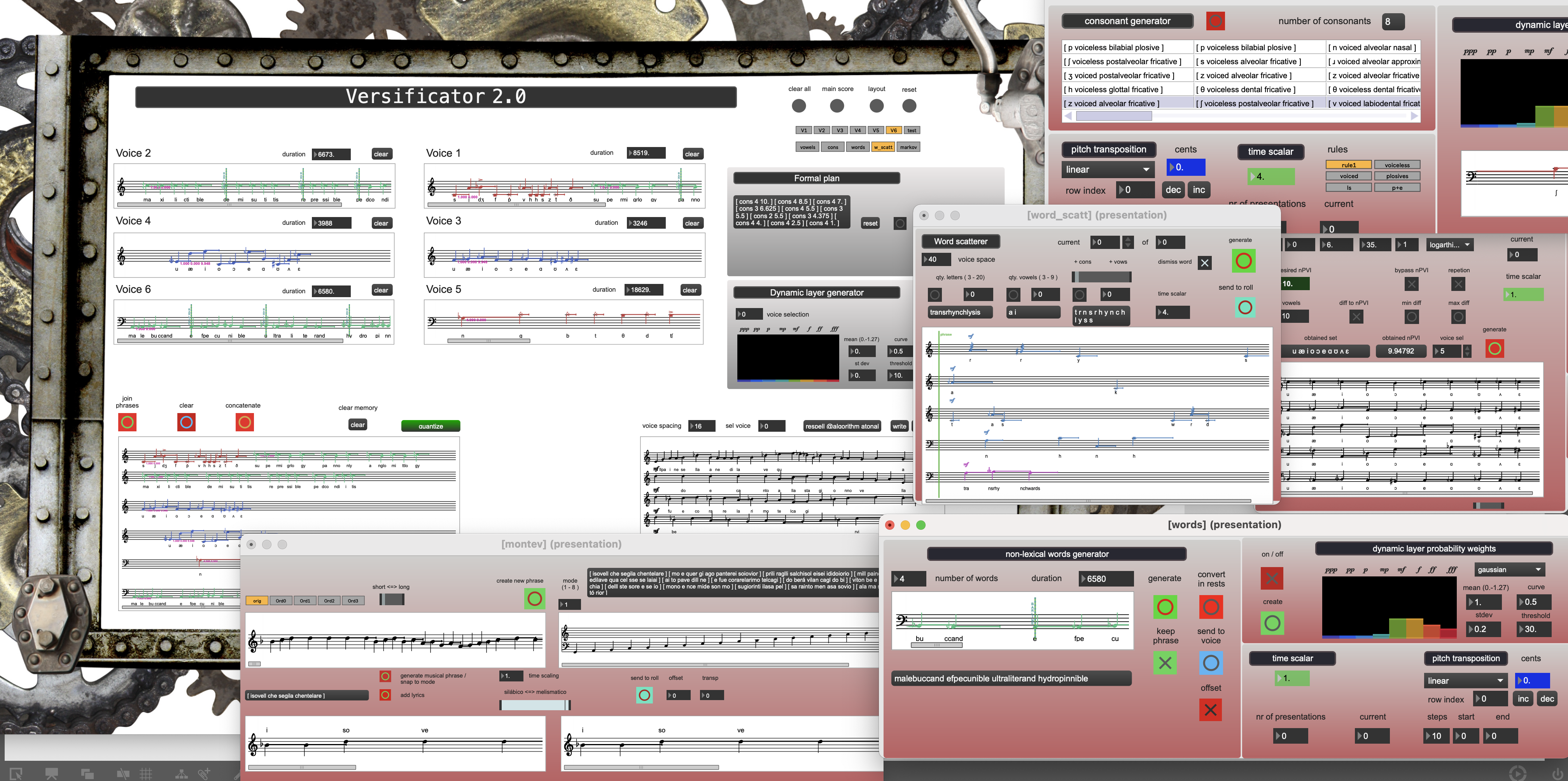
Musical material
The integral musical material of this piece is the phonological content of an imaginary language that nurtures itself with a merging of phonemes coming from Latin and English (see performance notes, pages. 1 and 2 of the score). A priori, this material is the search space that will be explored for the composition process. This phonological world materializes in three forms: (1) nonsensical words, (2) only vocalic, and (3) consonant sounds. Each of these forms comes out from three different generative modules. The generative core of the piece relies mainly on these three text generator modules plus a formal operator module.
Within each module exists a complex interaction between multiple constraint rules of different natures. The final complexity of the generated result is essentially derived from the chaining of simple rules. The outcome of each module is a musical unit –might well be labeled a musical phrase– consisting of both the generated text as the uttered text for a vocal part and its sonification as musical symbolic information in the form of pitches, durations, and vocal articulations.
Generative modules
The core creative process for this piece relies primarily on formal systems as strategies to materialize and organize musical material in a logically coherent manner. This logic is deeply rooted in sonic relationships, which are fundamentally spectral and temporal in nature. However, this organizational logic is expressed through logical statements in computer code, which serve as constraint rules for a generative process based on constraint algorithms. The parameters governing the generation and organization of the musical material –both at micro and macro levels– have been formalized as these constraint rules.
I have implemented two main types of rules. The first operates within each generative module, constraining the generation of text and its sonification into symbolic musical information. The second operates at a global formal level, governing the temporal distribution and textural organization of the outputs from each module.
The Nonsensical Canon*The Nonsensical Canon text generator is inspired by a program named “Words without sense” created by the artist Mario Guzmán (https://www.mario-guzman.com/), which outputs random combinations of prefixes, suffixes, and roots in Spanish or English. My version builds upon Guzmán’s work by adding the possibility of generating text using constraint rules.
The first module generates individual or sequences of sung nonsensical words –or pseudowords–*A nonsense word or a pseudoword is a unit of speech or text that appears to be a real word in a given language, as its construction follows the phonotactic rules of the language in question, although it has no meaning or doesn’t exist in the lexicon. which are the result of rule-based combinations of prefixes, roots, and suffixes of English and Latin words. Some rules that govern the generation of pseudowords have to do with the use of rhyme patterns,*A rhyme pattern applies to the ending of consecutive words. This is different from the notion of rhyme scheme, which applies to the final word of a stanza containing a determined number of syllables. alliteration, number of vowels or consonants, or proportion between them. For example, depending on how many words one generates –up to a maximum of 4– the rhyme pattern changes (for example, two words: aa; 3 words: aba; 4 words: abab.).

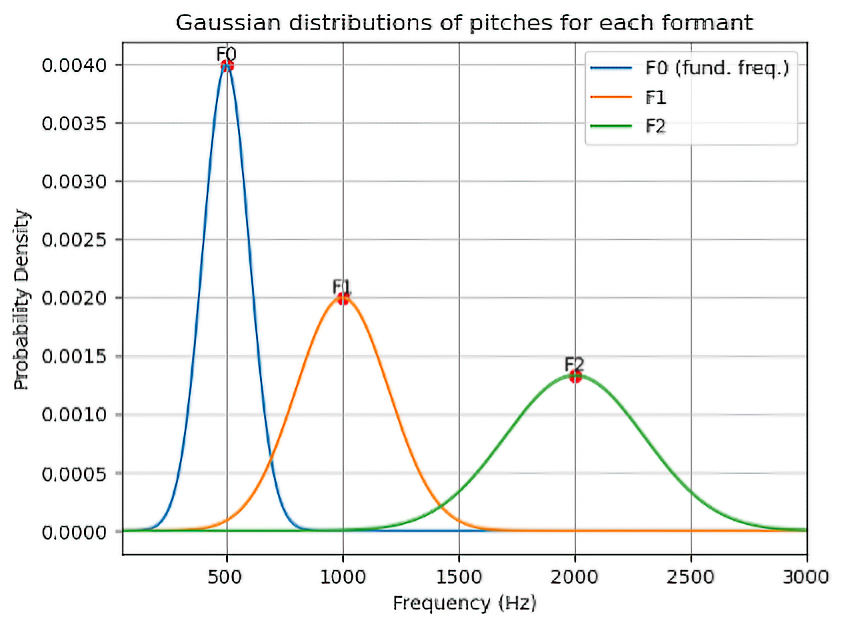
The symbolic sonification*I will discuss in depth the notion of symbolic sonification in the chapter ‘Joining the Threads.’ of the pseudoword occurs in stages. First, is it automatically hyphenated, and a musical pitch is given to each vowel in a syllable –similar to almost any sung text. These notes come from a database that contains information about the formant frequencies and duration of English language vocalic sound measurements.*James Hillenbrand et al., "Acoustic characteristics of American English vowels," Journal of the Acoustical Society of America 97, no. 5 (1995), https://doi.org/10.1121/1.411872. A different formant pitch will be assigned to each voice in the ensemble. The fundamental frequency will always appear in the lower voice, and the higher formants will appear successively in higher voices. The number of voices that should sing a pseudoword will determine how many notes from the formant structure should be sonified. The words thus are sung syllabically.


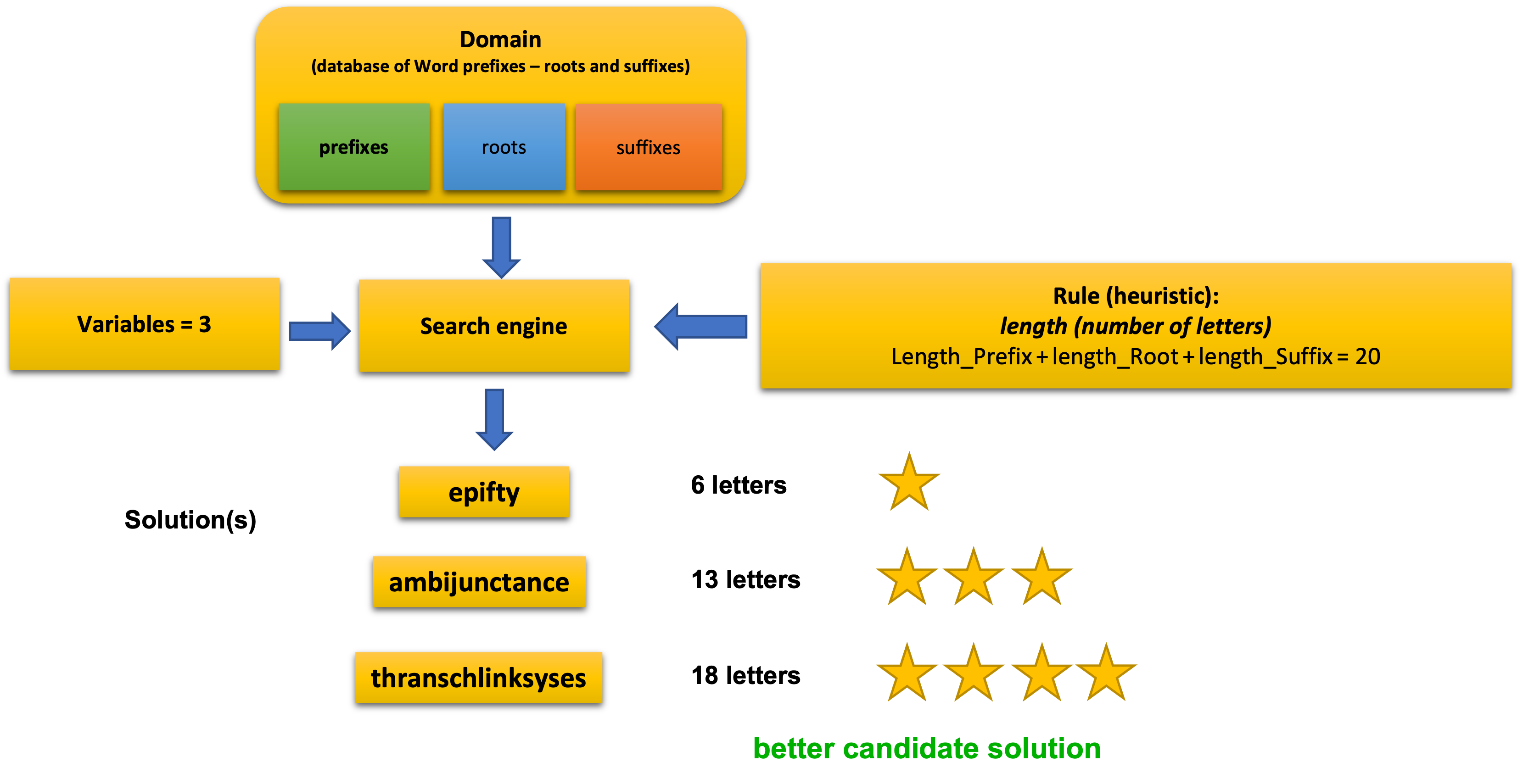
Below is illustrated how a heuristic rule that controls the number of letters for a word works. The search engine receives three variables: a prefix, a root, and a suffix for a word. The rule tells the engine to count letters for a different combination of variables and find the combination that is closer to 20.
Another example of generation that can be achieved by implementing heuristic rules is the construction of a set of words that have a variable proportion between vowels and consonants. Below is shown a sequence of words with a decreasing proportion of consonants (m. 41-94 of the score):
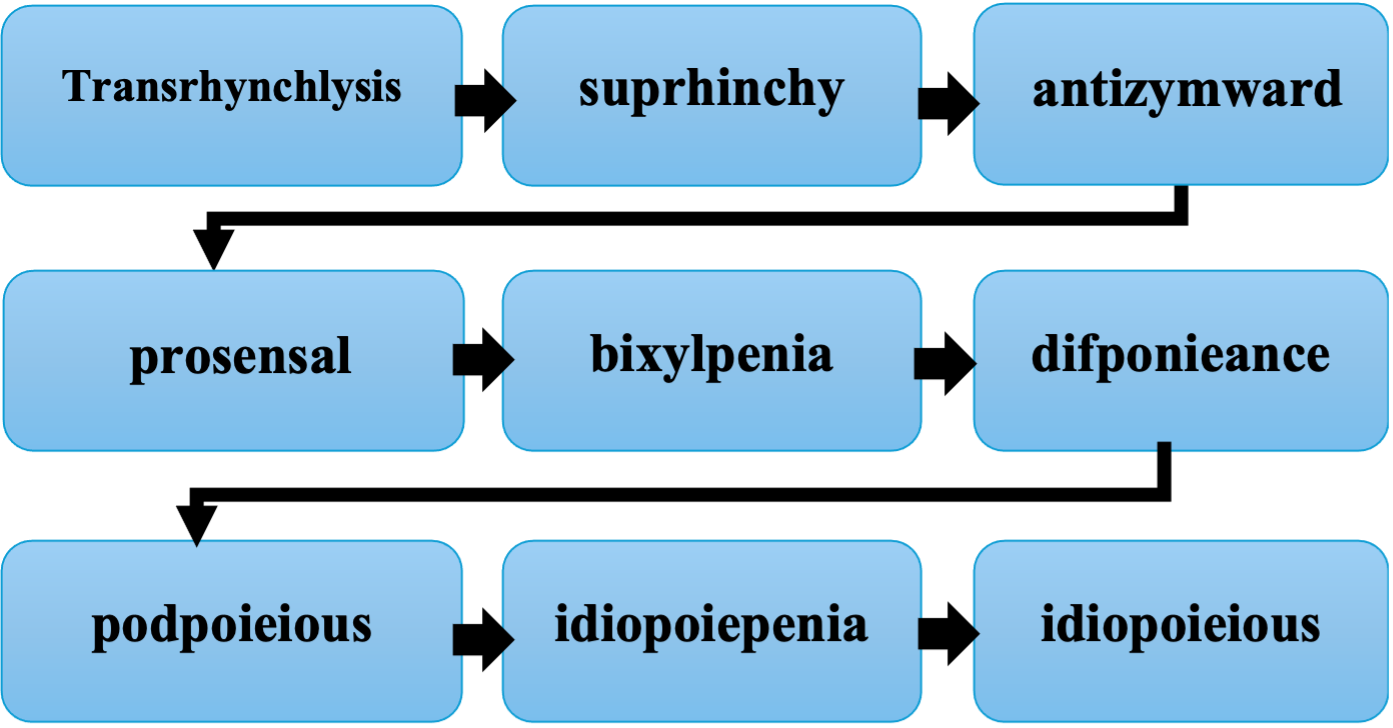
Another functionality of the Nonsensical Canon module allows one to scatter each word along the vocal texture. As a result, it is possible to hear the word in one of the voices and splinters of it in the rest of the texture (mm. 44-75 of the score).

The Vowel Choral module
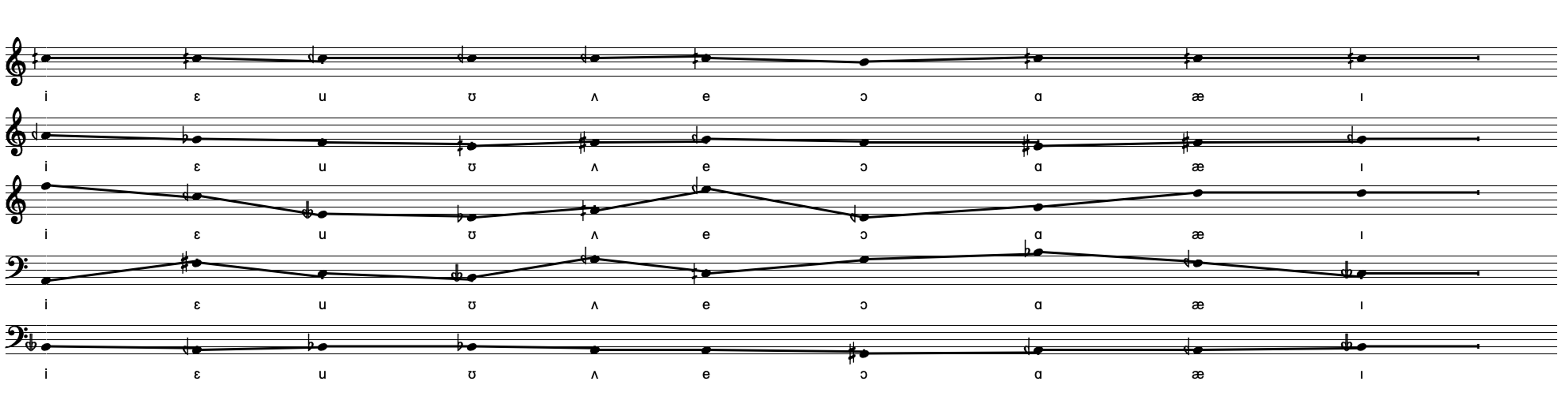
The second module, the Vowel Choral module, generates a sequence of vocalic sounds by sequentially ordering a set of predefined vocalic IPA symbols.*The International Phonetic Alphabet (IPA) is a standardized system of symbols used to represent the sounds of spoken language, aimed at ensuring accurate and consistent transcription of pronunciation across all languages. https://www.internationalphoneticalphabet.org/ As the source for the sonification of these vocalic sounds, I once again use the database of formants and durations from Hillenbrand’s study. However, I have introduced an additional parameter to constrain the generation of sequences: the contrastiveness between successive durations, measured using the nPVI index.*The nPVI index accounts for contrastiveness between the duration of successive speech sounds. It is used in acoustic phonetics as a measure to categorize languages. For more details see Francis Nolan and Eva Liina Asu , "The pairwise variability index and coexisting rhythms in language," Phonetica 66, no. 1-2 (2009), https://doi.org/10.1159/000208931 Esther Grabe, Francis Nolan, and Low Ling, "Quantitative Characterizations of Speech Rhythm: Syllable-Timing in Singapore English," Language and Speech 43, no. 4 (2000).
At the core of this module is a series of rules that constrain the organization of vocalic sound sequences based on their nPVI values. In essence, the module generates sequences resembling a choral, where each successive vocalic sound is more or less contrastive in terms of duration. The constraint engine enables this by allowing the generation of sequences with a desired nPVI, ranging from 5 (less contrasting) to 40 (more contrasting). Additional complementary rules can also be activated, such as whether repetition of any symbol is permitted and the length of the sequence, which can range from 2 to 12.*This module was further developed as a standalone abstraction named nPVIconstraints, which will be discussed further in the ‘Contributions’ section.

The Consonant Cloud module
The third module, the Consonant Cloud, generates sequences of consonants. The rules that constrain the generation of these sequences are based on phonetic features. According to the IPA chart, consonants can be classified according to (1) phonation –as voiced or unvoiced; (2) place of articulation –as bilabial, alveolar, velar, labiodental, dental, postalveolar, palatoalveolar and postalveolar,and (3) manner of articulation –as plosives, nasals, fricatives, and affricatives.
These constraint rules also depend on the number of parallel sequences that should be generated, each of them mapped to a voice of the ensemble. For example, it is possible to constraint a sequence to have four parallel lines containing only unvoiced sounds:

Below is an example of a more complex rule where independent lines are constrained to share some phonetic quality:
- Voice 1 and 2: equal phonation.
- Voice 3 and 4: equal place articulation.
- Voice 4 and 5: equal manner or articulation

Unvoiced consonants are notated as unpitched sounds. Voiced consonants are notated using pitches coming from the formant structure of a neutral vowel schwa (/ə/).

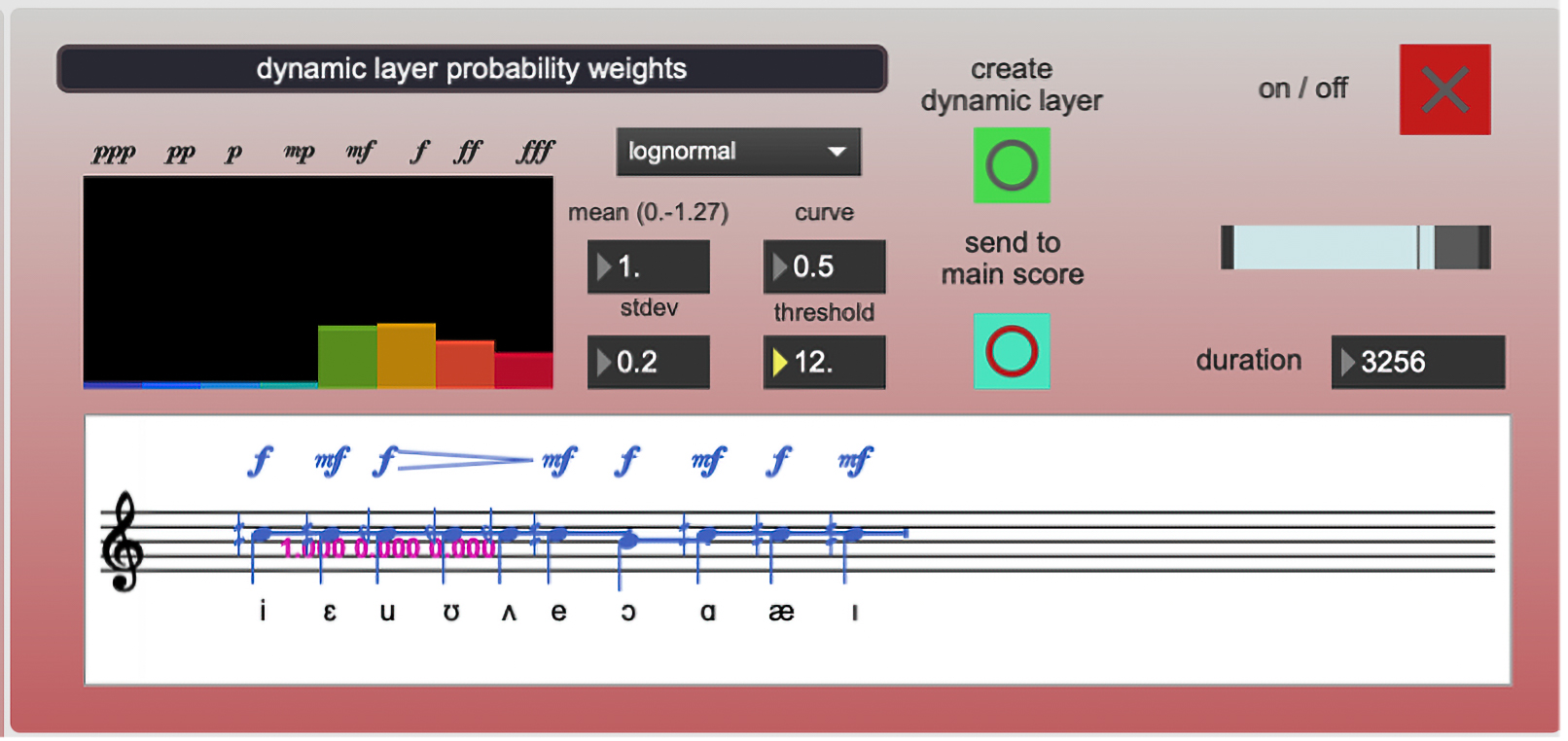
Dynamics submodule
Within each module, there is a dynamics generator submodule that allows the creation of a dynamic layer for the generated phrase. This layer is conceived in a probabilistic way. Namely, the submodule allows the creation of a probability distribution for all possible dynamics within a range (ppp to fff). Once this distribution is established, a dynamic layer can be created for each phrase or section (there is also a “general” dynamics submodule in the main user interface screen).
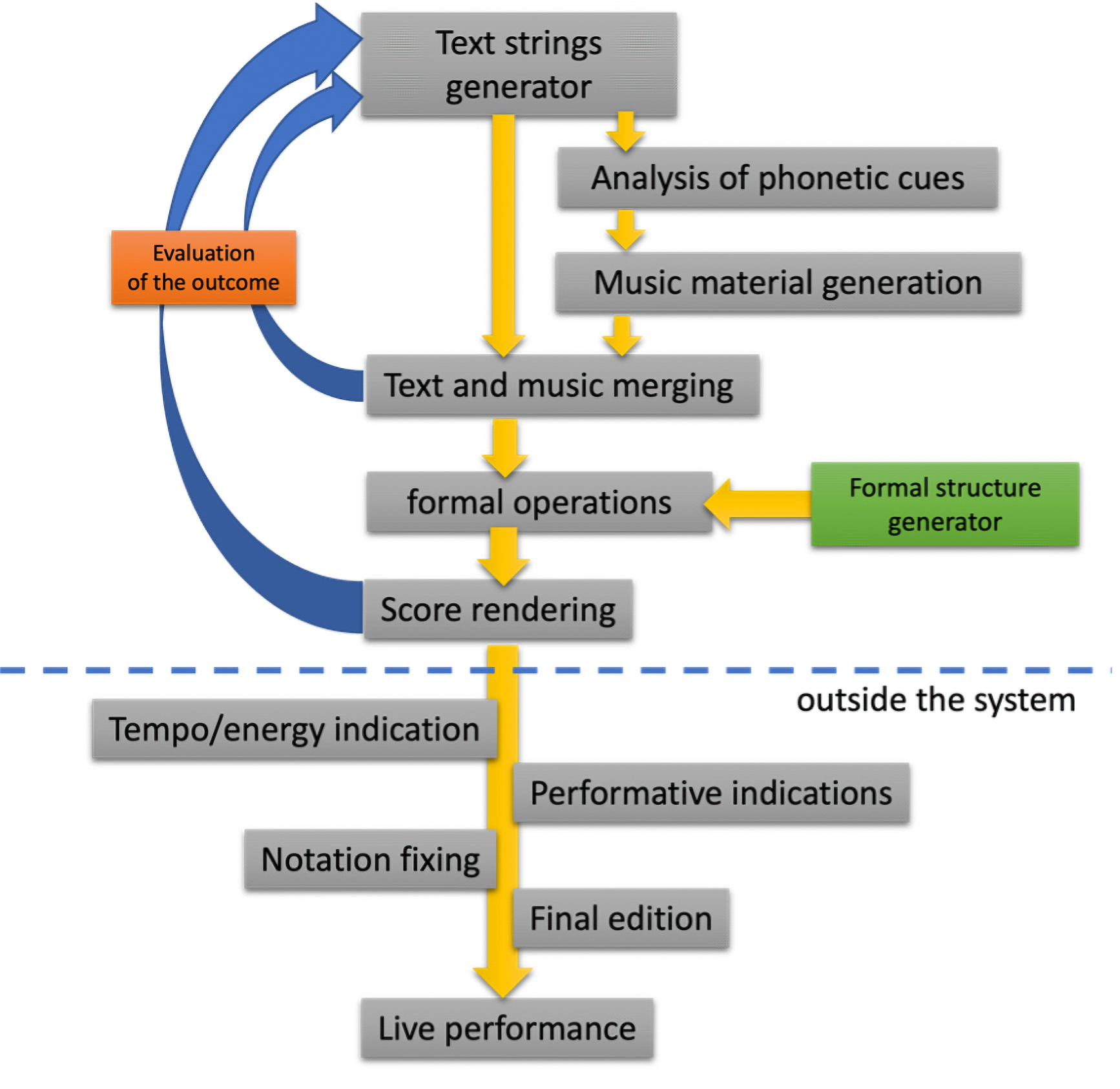
Composition/generation flow
As can be observed, my versificator is not a fully automated music score generator but rather facilitates an iterative creation process. Each generative module produces an output, and if the result is unsatisfactory, input parameters can be adjusted to generate different outcomes. The workflow for the system can be roughly outlined as follows:
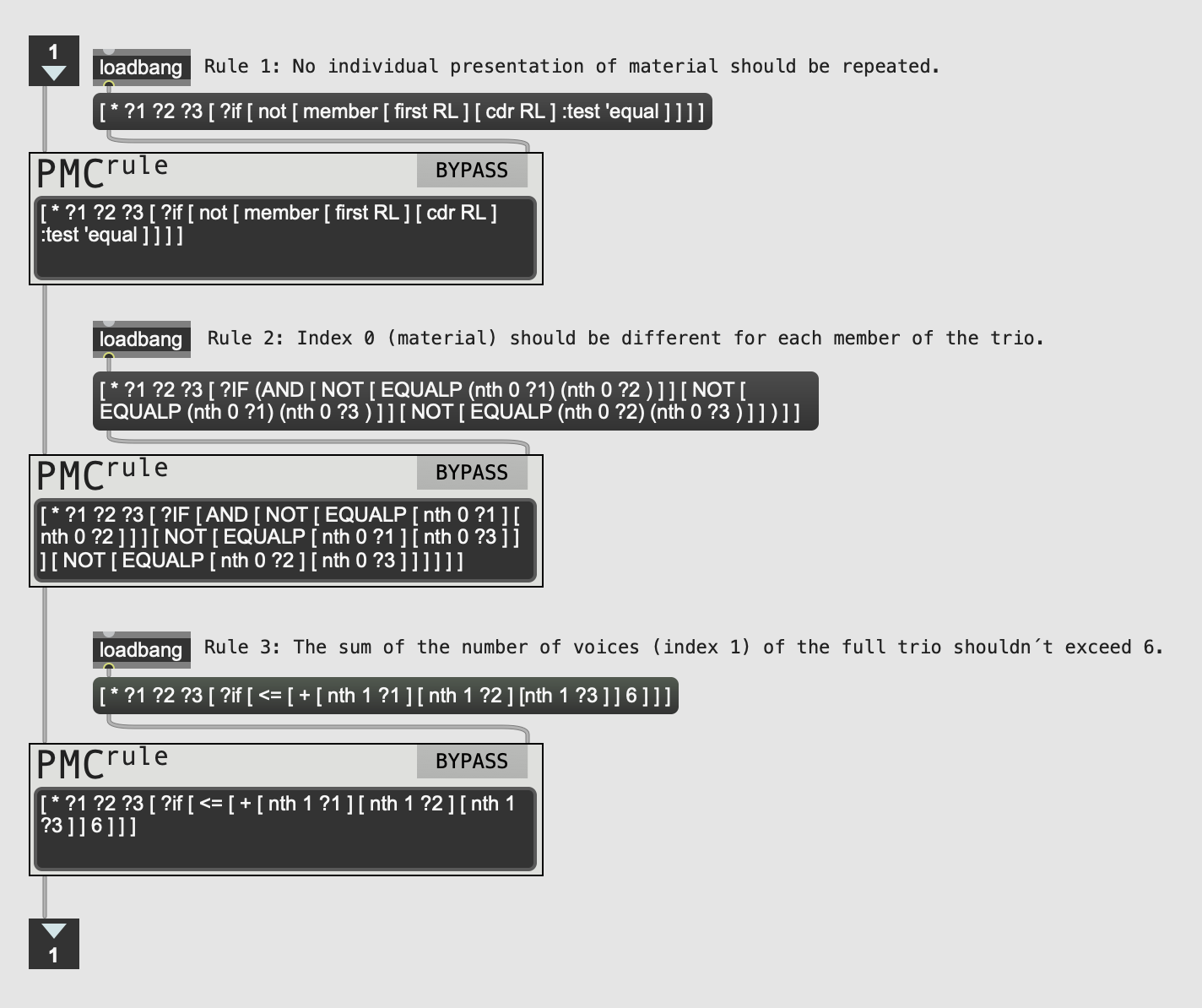
Formal organization
An independent module facilitates the formal and textural organization of musical material. The process of formal determination takes place before generating musical material with the modules, resulting in a list that includes the type of material –such as words, vowels, and consonants, time-scaling factor, and textural distribution of musical units that the modules should generate. This list serves as a formal blueprint, guiding the generation, combination, and concatenation of sentences within the modules.
The formal constraints are determined based on each musical unit’s possible duration, scaling factor, the number of voices in which it can appear, as well as the type of material and its combinatorial possibilities –in groups of two or three, depending on the number of voices in the ensemble. Within the module, these calculations employ stochastic methods based on probabilistic distributions and linear progressions –a detailed explanation of these processes will be left out of this text since it would take too much space.
Some examples of the rules used to determine the formal organization are:
- Presentations of materials can appear in duets or trios (for example, cons-vows, cons-words, vows-cons-words, etc.).
- Duos or trios cannot be composed of the same type of material.
- The sum of voices of each duet or trio of materials cannot exceed the number of voices determined for the vocal ensemble (by default, there are five voices).
- Alternative 1: Organize the pairs/trios based on the greatest possible contrast between the temporal scaling factors.
- Alternative 2: Organize the pairs/trios as close as possible to the mean of the scalar factor. Example: (1 x 10) / 2 = 5.5.
Outside the system
Some compositional decisions must necessarily be made outside the system. For a compositional decision to be made “outside the system,” it means two things. First, the specific musical parameter has been excluded from a constrained formalization. Second –and a rather practical aspect– most of this work is done “by hand” afterward.
At first glance, this suggests that the formal system –particularly the one based on constraints– did not extend to these specific compositional decisions. However, whether this is entirely true and whether other formal systems might apply to this compositional space remains less clear. The strictly iterative logic of computational constraints does not, of course, occur literally in the mind –no composer seriously considers every single combinatorial possibility of material. Instead, these decisions are heuristic-based, as will be shortly observed. Below, I will discuss some of the non-computational formalizations that took place “outside the system.”
Tempo
When determining the tempo of a section, I mainly care about determining a pace that would allow a listener to follow the levels of musical information delivered by the piece at that moment. This varies largely, depending on the type of material presented and the density of the texture as indicated by the formal blueprint. In addition, the choice of faster/slower tempi is sometimes related to the general character of the section, which is indicated with text indications –I will come back to this character indication later. The addition of rallentandos and accelerandos obeys mainly organic phrasing concerns and formal determination needs, for example, when a section ends, usually a rallentando is desired.
Dynamics
A probabilistic methodology for generating a dynamic layer is agnostic of any type of phrase structure or, even more problematic, is independent of how these sound materials should be orchestrated in the texture. For example, a given ppp dynamic for a group of unvoiced plosives together in the same phrase with a mf vowel choral material will likely cause “orchestration” problems, which would need to be later fixed “by hand” in the score. The dynamic layer generator, as originally ideated, will be most of the time flawed from this orchestrational point of view.
Although these orchestration problems weren’t always clear at first, once the piece was performed live by the ensemble, they became evident, and decisions had to be made. Ultimately, the solution to the dynamics issue had to occur “outside the system.” Additionally, the chosen set of dynamic possibilities now feels too restrictive, as some important nuances are missing –such as sforzatos. However, it seemed to work better when dynamic distributions were chosen for the phrases generated by each module based on their material composition, rather than applying overall dynamic layers to each compound phrase.
Intonation/tunning
The system allows me to choose from different microtonal grids –this is more a feature of the roll and score objects of the BACH library rather than an actual feature of the versificator. Initially, I chose quarter tones as the default tone division. However, I maintained the flexibility to switch to semitones in some sections to facilitate some singing lines that were very complex due to microtonal leaps. I stuck to the original microtonal division in the sections where there are glissandos –as these are easier to sing in tune. In these sections, the resulting harmonic constructs are dynamic, richer, and overall more interesting than those created with the semitone grid.
Case 1 – Statistical perturbations
After the first render of the piece, I realized that the sonification of vowels and their resulting chords felt too static and repetitive, as the phonological components of the voiced sounds –which provided the material for the harmonic content– were limited, leading to frequent repetitions of chords. To introduce some variation, I decided to modify how the system selects pitches for each harmonic field. Instead of mapping one-to-one a pitch for each formant, the system now picks weighted random pitches based on a Gaussian probability distribution, with the original pitch as the peak of the distribution. The width of the distribution –the range of pitches that can be chosen from– increases towards higher voices. As a result, chords typically vary microtonally/chromatically for the same vowel.
Case 2 – Mouth shapes
There is a prominent apparition of mouth shape symbols,*Initially, the idea of a timbral transformation of speech sounds through altering the shape of the mouth came to me from studying the pieces 'A painter of figures in room' (2007) by Aaron Cassidy and 'Al Ken Kara' (2012) by Dániel Péter Biró. especially in the first section (m. 1-39). After listening to the recording of a rehearsal of the first render of the piece, I had the sensation that using consonant sounds for a long time derived in a sonority that soon became quite static and timbrally homogenous for too long. I thought that adding a layer of timbral transformation by changing the shape of the mouth while pronouncing the phonemes would add some textural richness and open up a whole new compositional layer to develop.
The process of adding mouth shapes and dynamic transitions between them became a significantly time-consuming process. I did not follow a systematic approach to it, rather, I proceeded intuitively, mainly singing*The emphasis on the word singing is actually aimed at bringing up its embodied nature. This is an example of the use of a certain type of embodied knowledge for compositional purposes, but I will discuss it further later, in particular for the piece Elevator Pitch. each line myself and imagining the overall textural result. The addition of mouth shapes was done fully “outside the system.” Furthermore, following a logic was not systematic on the temporal dimension –order of apparition of each mouth shape, although these mouth shapes almost all the time are consistent across the voices, and usually, they overlap (see below).

This approach is heuristic, and it can be expressed as: the timbral shaping should remain consistent across all voices over time, but not necessarily identical –some diversity is welcome. This could potentially have been formalized as an additional layer within the Versificator system using a computational heuristic constraint rule.
Case 3 – Character indications
The sung character indications are potentially the most complex of all compositional layers –both inside and outside the system, though they look in the score quite straightforward: They came to my mind following a vague imaginary connection between the text in each section and an idea about what that text might mean in this imaginary language and, subsequently how it should be uttered. In my mind, the word “transchynklisys” (bar 41) sounded somewhat mysterious or metaphysical, the word “suphrinchy” (bar 50) more infantile. Therefore, it is asked to be sung as a toy, whereas the word “difponieance” (bar 75) sounded more solemn, or the words “homovirish abolish” (bar 139) sounded more religious. Therefore, I wanted them to be sung in a Palestrina-like style.
Another example starting on bar 95 comes the first vowel choral. This section, for some reason, gave me some psychedelic vibes, where one can hear how words slow down and stretch. Therefore, the indication in the score states that this section should “sound psychedelic (60s-ish).” Sometimes, character indications involve a sense of theatricality (for example, “as from radio news,” in m. 130). In some others, the singing technique changes dramatically, such as in m. 151 and 154. In most cases, however, the result of their interpretation is open to what each performer understands from them.

In summary, the character indications are fairly unspecific but serve as comments on my perception of the overall sonority desired for the section. The direct connection between a particular sonority –for instance, a phrase from the Vowel Choral– and a desired character indication cannot be mapped one-to-one to a semantic concept. However, in the case of pseudowords, these connections are more evident, as discussed above. They are often guided by semantic associations strongly influenced by the components of the pseudowords, for example, Latin prefixes, roots, or suffixes evoke religious semantic spaces, among others. While the mapping is not always immediately apparent, the connection is rather observable. This process, thus, is intuitive but shaped by strong semantic links between the pseudowords and a related character –or theatrical– indication, which influences the performer’s mindset and, consequently, their way of singing.
Final reflections
After listening to the recording of the premiere of the piece several times, I found some nice-sounding moments, for example, the beginning of the section on page 15 of the score with the glottal trill –added “outside the system”– (from m. 95), the intervention of the mezzo-soprano in bar 134 (“as from radio news”) and how it breaks the dynamic of the texture at that point; or the very end of the piece. The material is, in general, very homogenous: the text based on phonetic rules gives it uniformity in its sonority, and the rhyming pseudowords give it a poetic-imaginary quality that has a certain charm.

However, I must say that the interpretation by the performers of the character indications and those elements composed “outside the system” is what gives the piece something that otherwise would not have. What initially seemed to me like a marginal compositional space, ultimately became a fundamental part of the compositional process. As it can be observed, the overall compositional trajectory of the piece goes from almost no character indications to these indications flooding the whole texture around the climatic point, sometime around m. 157.
After this experience, the work with constraint rules and automation seems to me more rather like a starting than an endpoint for a deeper compositional refinement, especially outside computational formalizations. Even after a significant process of notation refinement and engraving, the piece, as it emerged originally from the versificator, seemed to be far from finished. It was still necessary to generate and refine new layers of compositional development outside the formalizations that the versificator operates. As I see it, the process of composition “outside the system” became the key to making an interesting piece: a type of marginal –and why not liminal– compositional space at the borders of the system became the soul of the work.


The artistic individuality of this piece likely extends far beyond computational formalizations and symbolic rules. While such an approach could potentially be refined to produce results with genuine artistic value, by itself, it ultimately fell short. A purely symbolic approach, therefore, proved insufficient to fully capture the nuances of the creative process for this piece, at least within this context.
These reflections reminded me of a quote by Lejaren Hiller:
“(…) when we raise this question of whether it is possible to compose music with a computer, we may note the following points: Music is a sensible form. It is governed by laws of organization that permit fairly exact codification. (…) Since the process of creative composition can be similarly viewed as an imposition of order upon an infinite variety of possibilities, an analogy between the two processes seems to hold, and the opportunity is afforded for a fairly close approximation of the composing process utilizing a high-speed electronic digital computer. In this context, it should be noted, however, that the composer is traditionally thought of as guided in his choices not only by certain technical rules but also by his “aural sensibility,” while the computer would be dependent entirely upon rationalization and codification of this “aural sensibility.”
This quotation resonates with a multitude of implicit questions that, I believe, remain historically significant even today. Hiller seems to ask whether it is feasible to formalize and codify a composer’s aural sensibility.*This inquiry became a lifelong mission for Hiller, although he built his research inquiries upon the work of mainly two pioneers: J. Schillinger and G. Birkhoff. See George David Birkhoff, Aesthetic measure (Harvard University Press, 1933); and Joseph Schillinger, "The Schillinger system of musical composition," Journal of Aesthetics and Art Criticism 8, no. 2 (1949).
This reflection has prompted several related questions: what is my own aural sensibility? What are my criteria for deeming a piece artistically valuable? Is this judgment based solely on my own subjectivity, or is it influenced by notions of what contemporary music should be, how it should sound, or even how it should appear on the score? What guides my auditory selection of algorithmic rules? Are these, ultimately, rules of style? If so, is this style rooted in a particular tradition? or institution? Did my knowledge of the intended performing ensemble influence my choice of rules and material? Clearly, it did. This leads to a broader question: how can we truly be creative beyond the bounds of these institutionalized constraints? And to what extent can we deviate from an established style when that very style defines our relevance as artists?
After composing this and other subsequent works, many of these questions lingered in my mind for some time. However, through the process of artistic research and reflection, I eventually began to articulate some ideas in response. I will revisit these thoughts in the ‘Conclusions?’ of this reflection.